
Kako je jedna kvačica na slovu “š” srušila interaktivnu igru na platformi MatematikaPro, zašto su “silent failovi” najgora vrsta bugova i kako smo to riješili hibridnom normalizacijom uz najnovije ažuriranje biblioteke Cro-Stem.
Zamislite scenu: Subota je navečer. Serveri se vrte, sučelje izgleda predivno, animacije su glatke i responzivne. Tiku, naša maskota kornjača, spreman je učiti djecu osnovama množenja u veseloj interaktivnoj igri “Tvornica Slatkiša”. Sve na prvi pogled izgleda savršeno i spremno za korisnike.
Ali ispod haube? Događao se potpuni kaos koji je prošao nezapaženo.
Interaktivna igra se odbijala učitati. Umjesto obećane šarene tvornice s animiranim elementima, sustav je djeci servirao obične, statične tekstualne zadatke na bijeloj pozadini. Nema greške na ekranu, nema crvenog uskličnika koji upozorava na kvar. Samo tišina i razočaravajući “fallback”. Ovo je priča o “Silent Fallbacku“, jednoj kvačici koja nas je koštala sati debugginga i proklinjanja “glupih” LLM-a i tehnologiji koja nas je na kraju spasila.
TIHI UBOJICA: UNDEFINED TEMA
Naš sustav na platformi MatematikaPro dizajniran je da bude ekstremno robustan. Ako bilo koji dio interaktivne igre (Game Engine) ne uspije pokrenuti grafički set podataka, sustav automatski prebaci na takozvani “Backup Mode”.
U tom modusu koristimo umjetnu inteligenciju da u hodu generira tekstualne zadatke kako dijete nikada ne bi vidjelo prazan ekran ili poruku o grešci. To je sjajno za korisničko iskustvo, ali za nas developere to je prava noćna mora jer skriva bugove.
Evo što se zapravo događalo duboko u kodu:
U našoj konfiguraciji tema (GameThemes.ts) ključ je bio zapisan ispravno: “Tvornica Slatkiša”. Međutim, u kodu samog motora igre (FactoryEngine.ts), programer (AI) je (slučajno ili iz navike) napisao:
GAME_THEMES[‘Tvornica Slatkisa’].
Vidite li problem?
JavaScript je nemilosrdan stroj: “Slatkiša” s kvačicom i “Slatkisa” bez nje su dva potpuno različita svijeta. Rezultat je bio “undefined” objekt. Kada je engine pokušao pristupiti postavkama teme, backend je “vrisnuo”, ali je taj vrisak odmah prigušen našim sustavom za oporavak koji je tiho pokazao obične zadatke.
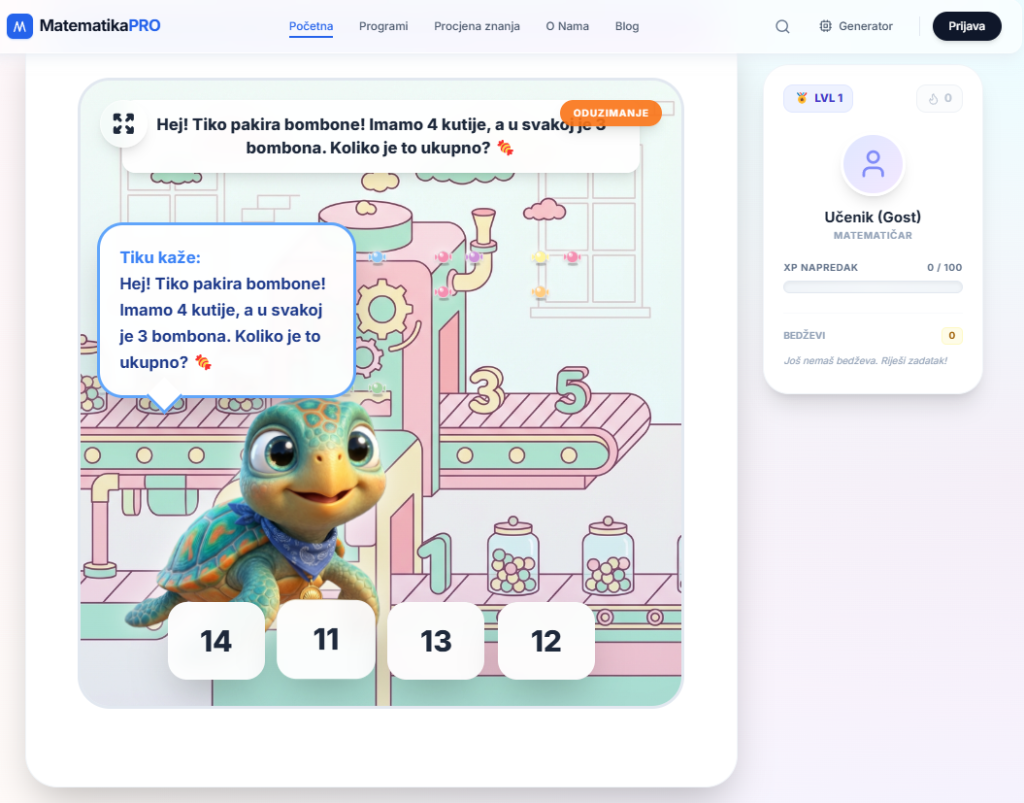
ZAŠTO JE OVO TAKO TEŠKO RIJEŠITI?
Programiranje na engleskom jeziku je relativno jednostavno jer je ASCII standard kralj. Ali programiranje lokaliziranih aplikacija za hrvatsko tržište je pravo lingvističko minsko polje. Imamo tri sukobljene strane:
- Konfiguracija mora biti čitljiva ljudima i pedagoški ispravna, pa koristimo hrvatske nazive poput “Tvornica Slatkiša”.
- Kod, s druge strane, povijesno teži sigurnosti i često bježi od kvačica kako bi se izbjegli problemi s enkodingom.
- Korisnik u našu tražilicu upisuje kako stigne – ponekad s dijakritikama, ponekad bez njih (npr. “mnozenje”, “množenje” ili čak “mnonjenje”).
Do sada smo se protiv ovoga borili “sirovom” snagom: pazili smo na svaku kvačicu i ručno ispravljali greške. No, ljudi griješe. Meni je trebalo rješenje koje razumije namjeru, a ne samo savršen niz znakova. Trebao mi je sustav koji razumije da je “š” zapravo “s” koji nosi šešir.
SPASITELJ: CRO-STEM 2.0 I HIBRIDNA NORMALIZACIJA
Srećom, baš u trenutku najveće borbe s ovim bugom, kao side projekt a upravo zbog MatematikaPro platforme spasio me moj open-sourc projekat (o kojem možete pročitati više ovdje) – Cro-Stem v0.1.7. Ova verzija je donijela revolucionarnu funkcionalnost: Hibridnu Normalizaciju.
Umjesto da tjeram AI ili korisnike na savršenstvo kod pisanja (jedno i drugo je nemoguće), sustav sada koristi “pametni filter” koji se sastoji od dva dijela:
- PHF Mapa: Izuzetno brza tablica najčešćih hrvatskih riječi koja trenutno prepoznaje da “slatkisa” znači “slatkiša”.
- Heuristika: Skup lingvističkih pravila koja procesiraju nepoznate riječi i “osjećaju” njihov korijen.
Implementirali smo novu klasu u naš backend koja procesira svaki ulaz. Sada, kada naš sustav traži temu, on više ne pita bazu “Je li ovo identično slovo po slovo?”. On postavlja puno pametnije pitanje: “Je li ovo ista stvar koju tražimo?”.

REZULTAT: 100% OTPORNOST NA LJUDSKE GREŠKE
Nakon što smo integrirali ovu tehnologiju, proveo sam niz testova koji su me za sad oduševili. Sustav je postao neprobojan:
- Input: “Tvornica Slatkisa” -> Odmah prepoznato kao “Tvornica Slatkiša”.
- Input: “tvornica slatkisa” -> Odmah prepoznato.
- Input: “TvOrNiCa SlAtKiŠa” (namjerno loš unos) -> Sustav i dalje nepogrešivo zna o čemu se radi.
Ovo nije bio samo usputni popravak buga. To je postala nova doktrina u razvojnoj arhitekturi. Više ne moram brinuti je li AI u nekoj dubokoj liniji koda zaboravio kvačicu.
Sustav je postao imun na taj specifičan problem, a naša interaktivna igra sada čvrsto stoji na nogama.
Što ovo znači za krajnje korisnike, prvenstveno djecu? To znači da naša tražilica sada “razumije” hrvatski jezik onako kako ga ljudi , (mi hrvati,srbi,bosanci,crnogorci) zapravo koriste.
Ako dijete napiše “mnozenje” bez kvačice, sustav više neće javiti grešku ili vratiti prazne rezultate. Odvest će ih točno tamo gdje trebaju biti – u srce učenja kroz igru.

ZAKLJUČAK
Bube u kodu su neizbježne, ali “tihi padovi” sustava su stvar izbora i arhitekture.
Naučio sam važnu lekciju da je rad uz učenje i rješavanje problema zaista najbolji način da nešto naučiš, čak i u ovo današnje vrijeme “AI će preuzeti svjijet” važno. Još važnije, naučio sam kolika je moć specijaliziranih alata koji razumiju specifičnosti našeg, hrvatskog jezika.
Cro-Stem 2.0 nije samo običan NLP alat. To je most između nesavršenih ljudskih unosa i preciznih strojeva. Ako radite na bilo kakvom hrvatskom tehnološkom projektu, toplo vam preporučujem da bacite oko na Cro-Stem GitHub. Spasit će vam sate debugginga i osigurati miran san.
Sada napokon mogu u miru ugasiti monitor i ne brinuti se što palim tokene na “gluposti” poput č,ž,š .
Sretan vibekoding!